Scrapy综述
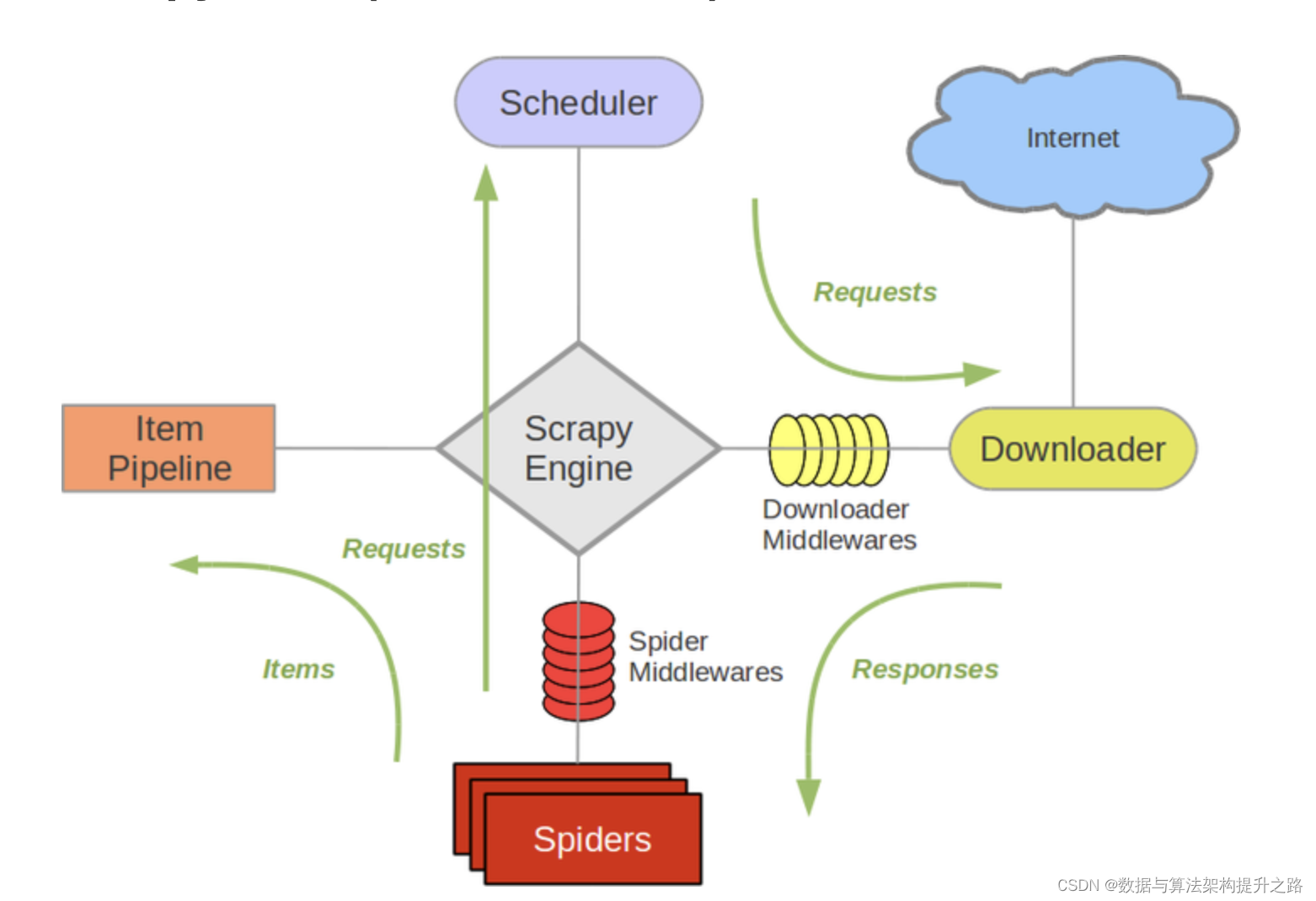
Scrapy总体架构
适用于海量静态页面的数据下载
-
Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。 -
Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。 -
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理, -
Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器), -
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方. -
Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。 -
Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
Scrapy的运作流程
代码写好,程序开始运行...
-
引擎:Hi!Spider, 你要处理哪一个网站? -
Spider:老大要我处理xxxx.com。 -
引擎:你把第一个需要处理的URL给我吧。 -
Spider:给你,第一个URL是xxxxxxx.com。 -
引擎:Hi!调度器,我这有request请求你帮我排序入队一下。 -
调度器:好的,正在处理你等一下。 -
引擎:Hi!调度器,把你处理好的request请求给我。 -
调度器:给你,这是我处理好的request -
引擎:Hi!下载器,你按照老大的下载中间件的设置帮我下载一下这个request请求 -
下载器:好的!给你,这是下载好的东西。(如果失败:sorry,这个request下载失败了。然后引擎告诉调度器,这个request下载失败了,你记录一下,我们待会儿再下载) -
引擎:Hi!Spider,这是下载好的东西,并且已经按照老大的下载中间件处理过了,你自己处理一下(注意!这儿responses默认是交给def parse()这个函数处理的) -
Spider:(处理完毕数据之后对于需要跟进的URL),Hi!引擎,我这里有两个结果,这个是我需要跟进的URL,还有这个是我获取到的Item数据。 -
引擎:Hi !管道我这儿有个item你帮我处理一下!调度器!这是需要跟进URL你帮我处理下。然后从第四步开始循环,直到获取完老大需要全部信息。 -
管道``调度器:好的,现在就做!
注意!只有当调度器中不存在任何request了,整个程序才会停止,(也就是说,对于下载失败的URL,Scrapy也会重新下载。)
Scrapy项目结构
Scrapy 2.11.2
Python 3.10.x
scrapy startproject tencent_job
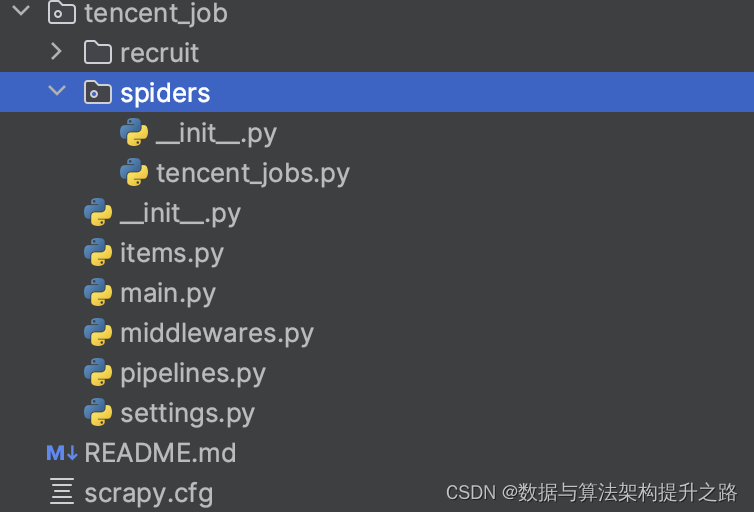
scrapy.cfg :项目的配置文件
tencent_job/ :项目的Python模块,将会从这里引用代码
tencent_job/items.py :项目的目标文件
tencent_job/pipelines.py :项目的管道文件
tencent_job/settings.py :项目的设置文件
tencent_job/spiders/ :存储爬虫代码目录
核心概念
Spider
Spider类定义了如何爬取某个(或某些)网站。包括了爬取的动作(例如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item)。 换句话说,Spider就是您定义爬取的动作及分析某个网页(或者是有些网页)的地方。
class scrapy.Spider是最基本的类,所有编写的爬虫必须继承这个类。
主要用到的函数及调用顺序为:
__init__() : 初始化爬虫名字和start_urls列表
start_requests() 调用make_requests_from url():生成Requests对象交给Scrapy下载并返回response
parse() : 解析response,并返回Item或Requests(需指定回调函数)。Item传给Item pipline持久化 , 而Requests交由Scrapy下载,并由指定的回调函数处理(默认parse()),一直进行循环,直到处理完所有的数据为止。
CrawlSpiders
CrawlSpider类定义了一些规则(rule)来提供跟进link的方便的机制,从爬取的网页中获取link并继续爬取的工作更适合。
通过下面的命令可以快速创建 CrawlSpider模板 的代码:
scrapy genspider -t crawl tencent tencent.com
Item Pipeline
当Item在Spider中被收集之后,它将会被传递到Item Pipeline,这些Item Pipeline组件按定义的顺序处理Item。
每个Item Pipeline都是实现了简单方法的Python类,比如决定此Item是丢弃而存储。以下是item pipeline的一些典型应用:
- 验证爬取的数据(检查item包含某些字段,比如说name字段)
- 查重(并丢弃)
- 将爬取结果保存到文件或者数据库中
process_request(self, request, spider)
-
当每个request通过下载中间件时,该方法被调用。
-
process_request() 必须返回以下其中之一:一个 None 、一个 Response 对象、一个 Request 对象或 raise IgnoreRequest:
-
如果其返回 None ,Scrapy将继续处理该request,执行其他的中间件的相应方法,直到合适的下载器处理函数(download handler)被调用, 该request被执行(其response被下载)。
-
如果其返回 Response 对象,Scrapy将不会调用 任何 其他的 process_request() 或 process_exception() 方法,或相应地下载函数; 其将返回该response。 已安装的中间件的 process_response() 方法则会在每个response返回时被调用。
-
如果其返回 Request 对象,Scrapy则停止调用 process_request方法并重新调度返回的request。当新返回的request被执行后, 相应地中间件链将会根据下载的response被调用。
-
如果其raise一个 IgnoreRequest 异常,则安装的下载中间件的 process_exception() 方法会被调用。如果没有任何一个方法处理该异常, 则request的errback(Request.errback)方法会被调用。如果没有代码处理抛出的异常, 则该异常被忽略且不记录(不同于其他异常那样)。
-
-
参数:
request (Request 对象)– 处理的requestspider (Spider 对象)– 该request对应的spider
process_response(self, request, response, spider)
当下载器完成http请求,传递响应给引擎的时候调用
-
process_request() 必须返回以下其中之一: 返回一个 Response 对象、 返回一个 Request 对象或raise一个 IgnoreRequest 异常。
-
如果其返回一个 Response (可以与传入的response相同,也可以是全新的对象), 该response会被在链中的其他中间件的 process_response() 方法处理。
-
如果其返回一个 Request 对象,则中间件链停止, 返回的request会被重新调度下载。处理类似于 process_request() 返回request所做的那样。
-
如果其抛出一个 IgnoreRequest 异常,则调用request的errback(Request.errback)。 如果没有代码处理抛出的异常,则该异常被忽略且不记录(不同于其他异常那样)。
-
-
参数:
request (Request 对象)– response所对应的requestresponse (Response 对象)– 被处理的responsespider (Spider 对象)– response所对应的spider
防止爬虫被反主要策略
有些些网站使用特定的不同程度的复杂性规则防止爬虫访问,绕过这些规则是困难和复杂的,有时可能需要特殊的基础设施
-
动态设置User-Agent(随机切换User-Agent,模拟不同用户的浏览器信息)
-
禁用Cookies(也就是不启用cookies middleware,不向Server发送cookies,有些网站通过cookie的使用发现爬虫行为)
- 可以通过
COOKIES_ENABLED控制 CookiesMiddleware 开启或关闭
- 可以通过
-
设置延迟下载(防止访问过于频繁,设置为 2秒 或更高)
-
Google Cache 和 Baidu Cache:如果可能的话,使用谷歌/百度等搜索引擎服务器页面缓存获取页面数据。
-
使用IP地址池:VPN和代理IP,现在大部分网站都是根据IP来ban的。
-
使用 Crawlera(专用于爬虫的代理组件),正确配置和设置下载中间件后,项目所有的request都是通过crawlera发出。
DOWNLOADER_MIDDLEWARES = { 'scrapy_crawlera.CrawleraMiddleware': 600 } CRAWLERA_ENABLED = True CRAWLERA_USER = '注册/购买的UserKey' CRAWLERA_PASS = '注册/购买的Password'
设置下载中间件
下载中间件(Downloader Middlewares)在Scrapy架构中扮演着至关重要的角色,主要功能是在Scrapy的请求(Request)和响应(Response)处理过程中提供一个可插拔的钩子系统。这允许开发者在请求发送到服务器以及服务器返回响应的过程中插入自定义的处理逻辑。
下载中间件是处于引擎(crawler.engine)和下载器(crawler.engine.download())之间的一层组件,可以有多个下载中间件被加载运行。
-
当引擎传递请求给下载器的过程中,下载中间件可以对请求进行处理 (例如增加http header信息,增加proxy信息等);
-
在下载器完成http请求,传递响应给引擎的过程中, 下载中间件可以对响应进行处理(例如进行gzip的解压等)
下载中间件在Scrapy项目的settings.py文件中配置。您需要在DOWNLOADER_MIDDLEWARES设置中添加自定义中间件类,并分配一个整数值来确定它们的执行顺序。数值越小,中间件越早执行
这里是一个例子:
DOWNLOADER_MIDDLEWARES = {
'mySpider.middlewares.MyDownloaderMiddleware': 543,
}
编写下载器中间件十分简单。每个中间件组件是一个定义了以下一个或多个方法的Python类:
class scrapy.contrib.downloadermiddleware.DownloaderMiddleware爬取腾讯工作的项目实战
sevnce-crawler: 爬虫相关技术 - Gitee.com
scrapy爬取招聘网站数据实战
相关资料
聚焦Python分布式爬虫必学框架Scrapy打造搜索引擎(二)-CSDN博客
Python的Requests来爬取今日头条的图片和文章_cookie池维护-CSDN博客
链接: 百度网盘 提取码: qc48


![P1107 [BJWC2008] 雷涛的小猫](https://img-blog.csdnimg.cn/img_convert/4a1934f72540cb516e26dbae05c39732.png)


![[数据库]mysql用户管理权限管理](https://img-blog.csdnimg.cn/direct/8f20e352fa2d4de6b09b6e9cd1ece0c9.png)